Many people think software quality is subjective. Fortunately, this couldn’t be further from the truth. There are metrics you can use to have meaningful conversations about code, and one of the most valuable is cyclomatic complexity.
Don’t let the complicated-sounding name scare you!
As you’ll soon see, cyclomatic complexity is easy to understand and calculate. This is great since it has important implications for code maintainability and testing.
By the end of this post, you’ll know
- what cyclomatic complexity is
- how it’s calculated
- why it’s important
- why and how you should reduce it
Let’s get started.

The Definition
Cyclomatic complexity is a metric that indicates the possible number of paths inside a code artifact, e.g., a function, class, or whole program. Thomas J. McCabe Sr. developed this metric, first describing it in a 1976 paper.
The higher the cyclomatic complexity, the more possible ramifications there are inside a given code excerpt. For instance, a function with a cyclomatic complexity of 1 will always go through the same execution path. Conversely, a function with a cyclomatic complexity value of 8 will have eight possible execution paths.
All else being equal, having a lower complexity is usually better. More on that later, though. For now, let’s look at how to calculate it.
The Calculation
Let’s look at how to calculate the cyclomatic complexity.
For starters, bear in mind that you don’t actually need to calculate it. The IDE you use to code most likely already has this functionality built in.
Regardless, let’s look at how you would calculate it so you can understand what this metric is about.
The classical way to calculate cyclomatic complexity is through McCabe’s Formula. I cite Wikipedia:
The complexity M is then defined as M = E − N + 2P,
whereE = the number of edges of the graph.
N = the number of nodes of the graph.
P = the number of connected components.
Translating it into simpler language, it works like this: You transform your code into a graph. Each node in the graph is a statement of the code. The edges are what connects the nodes. Finally, P simply means the exit point of the program or routine.
Imagine a function with three consecutive statements and no structure or decision statement. Its graph would look like this:
[] -> [1st statement] -> [2nd] -> [3rd] -> [exit]
We have five nodes, four edges, and one connect component. Let’s replace all of that in the formula:
M= 4 - 5 + (2 * 1)
Thus, the complexity of this function is one.
Cyclomatic Complexity Examples
As you saw in the last section, for the simple cases, calculating the cyclomatic complexity isn’t needed because you can literally see it. To drive the point home, I’ll walk you through an example of cyclomatic complexity in practice.
I’ll use a single function as an example, progressively increasing its complexity as we go. The examples will be in C# for the simple reason that it’s my go-to language. They should be easy to understand regardless of your language preferences.
Cyclomatic Complexity = 1
Consider the following function:
public static string IntroducePerson(string name, int age)
{
var response = $"Hi! My name is {name} and I'm {age} years old.";
return response;
}
As you can see, the function above has a single execution path. The results will be different, of course, depending on the values passed as parameters. But the code itself will always go through the same path. Visually, we can represent the function above with the following diagram:
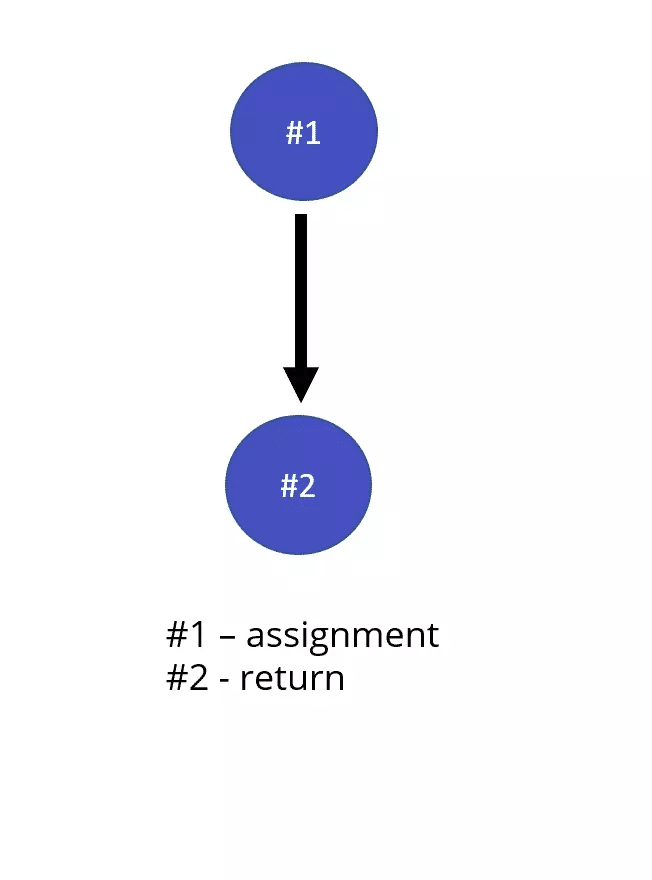
The function has a complexity of 1.
Cyclomatic Complexity = 2
Now let’s make a small change to the function:
public static string IntroducePerson(string name, int age)
{
var response = $"Hi! My name is {name} and I'm {age} years old.";
if (age >= 18)
response += " I'm an adult";
return response;
}
The function now has a logical branch. If the age is equal to or greater than 18, the text “I’m an adult” will be concatenated to the response. There are two possible execution branches in the code. Visually, we can represent the function like this:
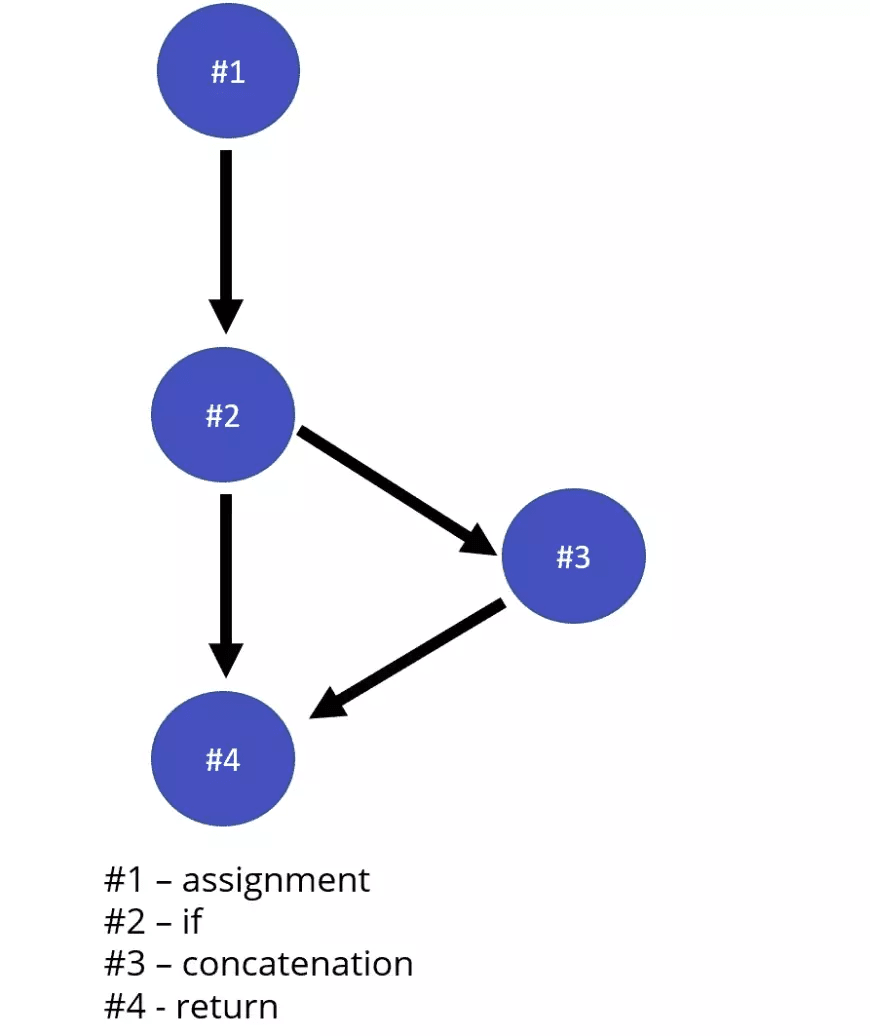
Cyclomatic Complexity = 3
Let’s consider yet another change to the function, the addition of a new if statement:
public static string IntroducePerson(string name, int age)
{
var response = $"Hi! My name is {name} and I'm {age} years old.";
if (age >= 18)
response += " I'm an adult.";
if (name.Length > 7)
response += " I have a long name.";
return response;
}
We now have yet another branching that verifies the length of the person’s name. This makes the cyclomatic complexity of the function reach 3.
You might wonder: why three and not four? It’s easy to understand. Each additional if adds another potential forking in the road. So the function starts at 1, the first if adds a potential new branch, and the second if adds yet another potential branch, totaling 3.
See the diagram:
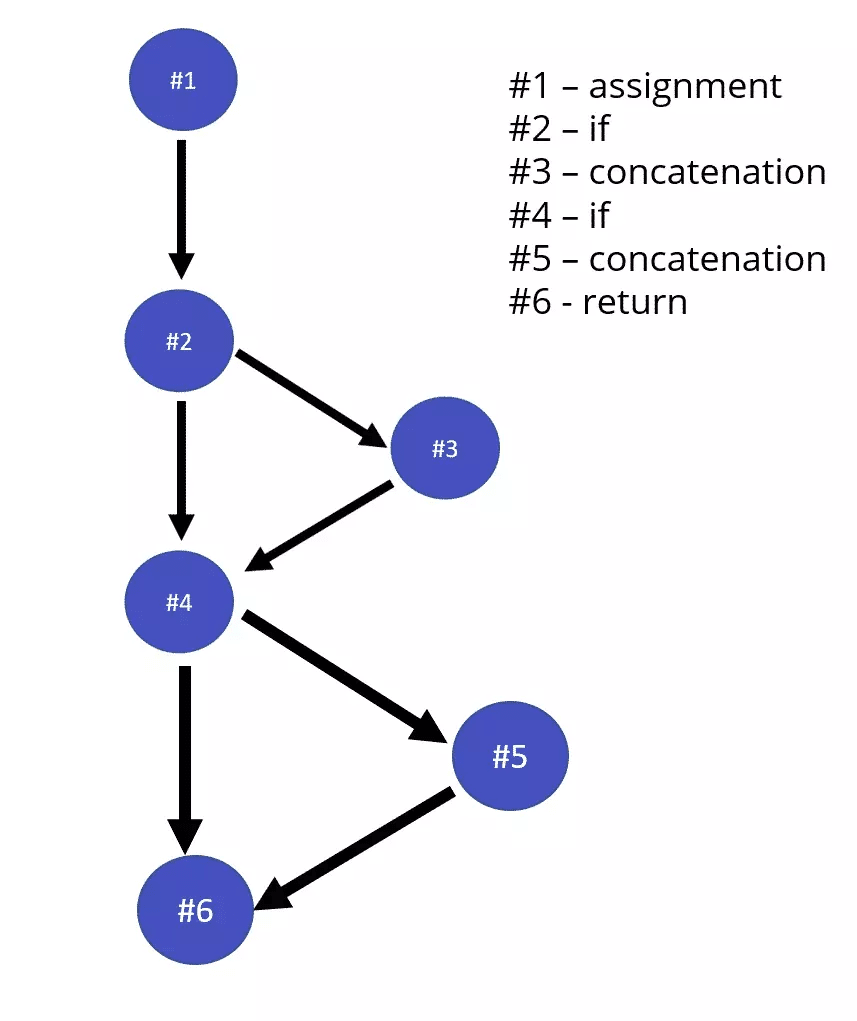
The Why of Cyclomatic Complexity
Having covered the what and the how of cyclomatic complexity, there’s only one major question left: the why. We’ve mentioned before that, all else being equal, you should strive for a low value of cyclomatic complexity. Let’s look at why that’s the case now.
Complex Code Is Often Hard to Understand
Cyclomatic complexity is, unsurprisingly, one of the contributing factors to code complexity. Generally speaking, the higher the cyclomatic complexity of a given piece of code, the harder it is for engineers to understand it. We often call that the cognitive complexity of code, and it’s a predictor of bugs and other issues.
However, the relationship of cyclomatic complexity with cognitive complexity isn’t always that clear-cut. It’s possible to have methods with high cyclomatic complexity that are easy to understand.
The opposite is also true. You can have methods with low cyclomatic complexity that are hard to reason about. Methods that rely on side effects are a great example.

Cyclomatic Complexity Is Related to Testing
Cyclomatic complexity is a metric intimately related to testing. It’s easy to see why: the more possible execution branches a given piece of code has, the more test cases you’ll need to ensure that all possibilities are covered. If you’re going for full branch coverage, the cyclomatic complexity value is the number of test cases you’ll need.
The main takeaway here is that keeping cyclomatic complexity low will make testing easier (at least at the unit level — higher layers of the testing pyramid, typically executed in test environments, have their own difficulty factors).
Keep Your Cyclomatic Complexity at Bay
Cyclomatic complexity is one of the most valuable software development metrics. It plays a major role in the overall code complexity of a given piece of code. Also, and perhaps more importantly, it’s a metric intimately related to testing.
As you’ve seen in this post, generally speaking, keeping the cyclomatic complexity of your code low is desirable. How can you achieve that?
While we do have an entire post showing how to reduce cyclomatic complexity, here is a summary:
- Write small functions. The smaller the function, the less likely it is to have high complexity.
- Avoid flag parameters. Flag arguments necessarily introduce more complexity due to the need for decision structures.
- Leverage design patterns. Use design patterns to your advantage. For instance, strategy can help you reduce the need for if statements. The template method can help you get rid of code duplication.
- Avoid NIH syndrome. Don’t reinvent the wheel. When it makes sense, leverage third-party code in the forms of open-source libraries and frameworks. Also, don’t write code if the same functionality already exists in your standard library.
Before wrapping up, there’s an additional use of cyclomatic complexity I need to mention. This metric is also helpful to identify high-risk areas in your application. For instance, say you have an area in your codebase that, besides having a high cyclomatic complexity, also gets a lot of rework. That part of the application deserves of a lot of attention.
LinearB is a tool that can help you identify such risky areas. With its dashboard, you can correlate Jira analytics with Git statistics in a way that gives you a unique view of your team’s performance. Start your LinearB demo today.