Table of Contents
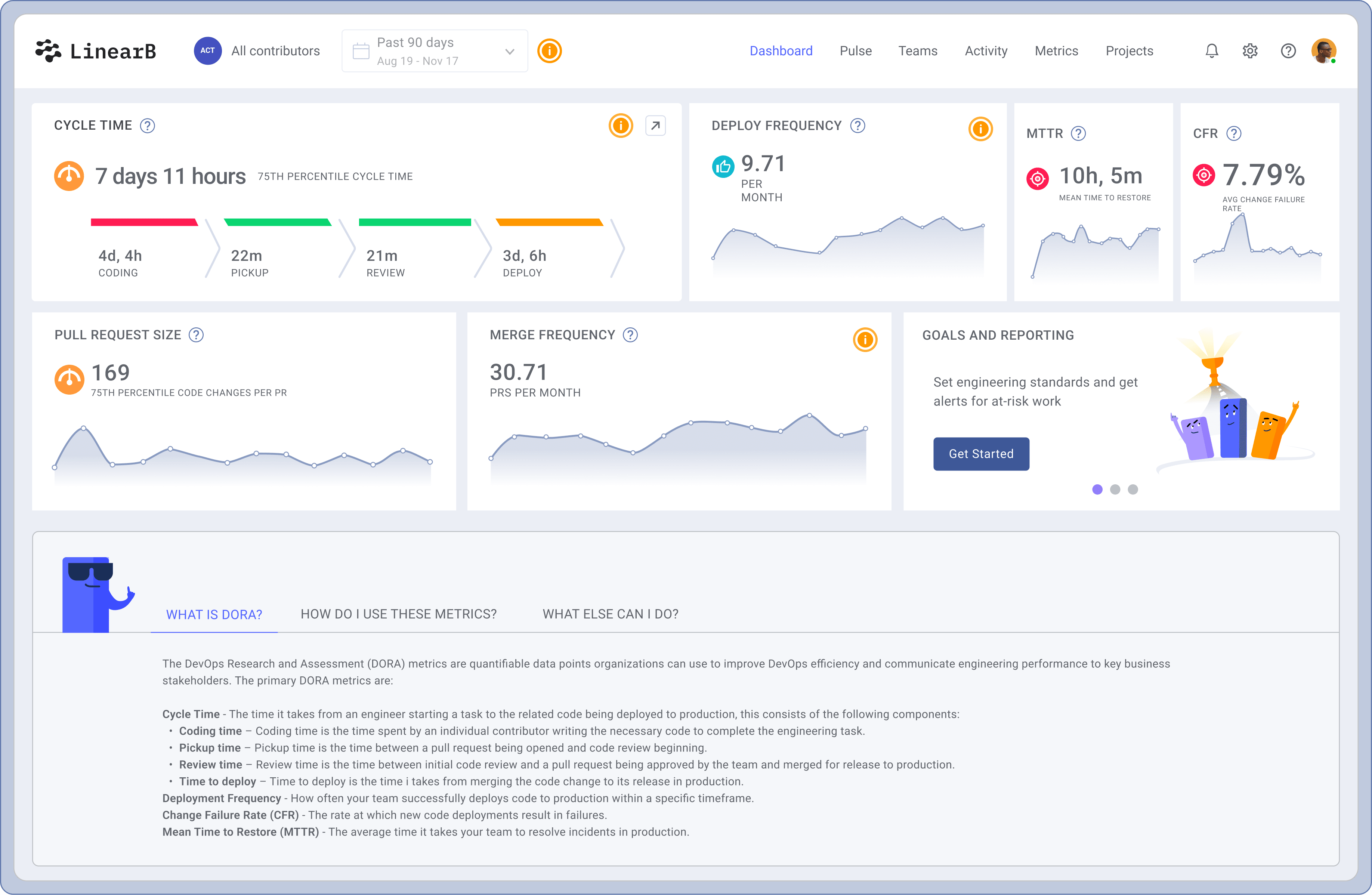
If you’d like to learn more about these concepts or see the capabilities discussed in this blog in action, schedule a demo of LinearB today!
If you’d like to jump right in, you can get a totally free forever LinearB account right here.
Further Reading


Join our community of data-driven dev leaders
Each week we share stories and advice from engineering and product leaders striving to be better for their teams.
LinearB may send you email occasionally about how you can optimize productivity.
We will not share your information with anyone. Ever.