Code coverage used to be a slightly controversial topic for software developers. I remember discussions about why it doesn’t make sense to aim for 100% code coverage (unless you’re programming extremely critical systems with big budgets). More on that later.
But code coverage has become a mainstream metric for code quality that helps teams maintain their code. And there are different ways to calculate code coverage. So, which number should you be looking at?

How Code Coverage Works?
Let’s briefly look at what we’re trying to achieve with code coverage because this can help us determine which type of code coverage is best.
Code coverage is a metric that tells you what percentage of your code is covered by tests.
Notice that I didn’t say unit tests. Basically, any type of test can contribute to your code coverage; although I’m assuming the tests are automated. If the tests aren’t automated, we can’t reliably measure the code coverage over time.
But as long as they are automated, you can run all your tests and have a tool count the pieces of code that were executed. In fact, if you have unit tests, integration tests, and end-to-end tests, you would probably like to combine the results into a single report.
The power of code coverage is in the report.
First of all, you’ll get an overall percentage. For example, the tool might tell you that your tests cover 67% of your code.
That’s not bad, but it leaves some room for improvement. (I’m happy when my team reaches 80%.) So, you know you need to add tests.
You can also set up your CI/CD pipeline to fail if code coverage drops below a certain percentage. This encourages the team to add tests as they add new code. And when the code coverage increases, you can increase the minimum required as well.
The overall percentage isn’t the only interesting thing. Modern code coverage tools will also show you a detailed view of code coverage per module, file, class, or method. This allows you to identify areas with low code coverage that you might want to look at first. Take this report, for example:

Ignore all those numbers for a moment. They indicate the different types of code coverage. The interesting bit now is that we can see that there are three folders or modules that have a high enough code coverage value. But the src/routes/account/media folder can use some extra tests and the src/routes/account/settings/email/middleware folder definitely needs more tests.
So, the code coverage report can tell us where we need to focus first.
Tools like LinearB can also assist with prioritization by detecting high-risk work, i.e. branches with more than 100 code changes with over 50% of these changes being rework or refractor work. The more code changes we merge back to the code base, the higher the chance some are not thoroughly reviewed, checked, and tested.
The Idea Behind Code Coverage
Why do we need to aim for a high code coverage value? What value do we get out of it?
A well-tested codebase is usually (but not always) a well-structured codebase. This means it will be easier for developers to modify the code or add new features. They’ll also feel safer in doing so, as a good test suite provides a safety net for changes.
This means they’ll feel more confident in making changes that keep up the code quality. If they break something, they know there’s a big chance that the software testing will catch the bug they introduced. And we’d rather catch the bug while writing the software instead of having end users notify us, right?
So, that’s why you want a good code coverage value. Because it’s a measure of how well our code accepts change without breaking. As Kellet Atkinson, Director of Product at DZone, puts it, “the more test coverage you have, the less likely you are to roll back your code.”
The Different Types of Code Coverage
Let’s put that aside for a moment and look at the different types of code coverage (all those numbers in our report). After that, we’ll use the above reasoning to choose the best one for us.
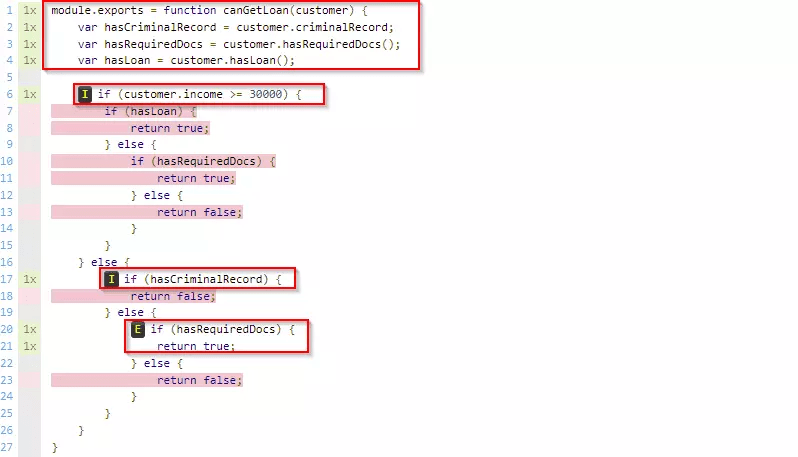
Take a look at this (made-up) JavaScript code:
module.exports = function canGetLoan(income, criminalRecord, hasRequiredDocs, hasLoan) {
var hasCriminalRecord = customer.criminalRecord;
var hasRequiredDocs = customer.hasRequiredDocs();
var hasLoan = customer.hasLoan();
if (customer.income >= 30000) {
if (hasLoan) {
return true;
} else {
if (hasRequiredDocs) {
return true;
} else {
return false;
}
}
} else {
if (hasCriminalRecord) {
return false;
} else {
if (hasRequiredDocs) {
return true;
} else {
return false;
}
}
}
}It’s an overly complex way of determining whether or not someone can get a loan at a bank. I realize I should drastically improve this code. But let’s assume the real code is much more complex (which I have seen), and software developers are afraid to change it.
In order to take away the fear, you set about adding tests. Here’s a first test:
const canGetLoan = require('../src/index');
const expect = require('chai').expect;
describe('canGetLoan', () => {
it('should return true for someone with a lower income, no criminal record, the required docs and no existing loan', () => {
const customer = {
income: 20000,
criminalRecord: undefined,
hasRequiredDocs: () => true,
hasLoan: () => false
};
const result = canGetLoan(customer);
expect(result).to.be.true;
});
});When we run this with a code coverage tool (nyc in this case), this is what our report looks like:

See how there are four numbers at the top? Let’s dive deeper into what those four types of code coverage mean.
Line Coverage
The first type we’ll look at, line coverage, is probably the oldest way of calculating code coverage. It basically measures the number of lines your tests executed as a percentage of the total number of lines. In our example, the lines of code with else or with brackets aren’t counted because they don’t contain anything to execute. That means a total of eight out of 15 lines were executed:
This gives us 53.33% code coverage.
Statement Coverage
Statement coverage tells you how many statements were covered. If you’re like me, every statement is on its own line, and the coverage percentage is the same (53.33% in our test case). But you might have code where there are two or more statements on a single line. Let’s change our code to contain a line like this:
var hasCriminalRecord = customer.criminalRecord; var hasRequiredDocs = customer.hasRequiredDocs();
Now, if we run our tests and look at the report, we can see that we executed eight of the 15 statements but seven of 14 lines:

So, statement coverage would be a better metric; although, you might just want to have those two numbers be the same.
Why do tools still calculate line coverage? Basically, this is for integrating with older tools that can only handle line coverage.
Function Coverage
Function coverage criteria is simply how many of your functions are under test. In our example, we only have a single function. And we called it in our test, so our function coverage is 100%.
The value of function coverage is in identifying functions that aren’t tested at all, even if you have a high value for the other types of code coverage. Let’s take a look at the headers of our first (fictional) report:

Here, we can identify the areas that still have untested functions.
Look at the src/routes/account/settings/email line, for example. It has a statement coverage of 84.62%, which we think is good. But it has a function coverage of 77.78%.
There are two functions that aren’t executed at all. That’s something to look into.
Branch Coverage
The last type of code coverage we see in our example report is branch coverage (or decision coverage). A branch can occur because of an if statement, of course, but switch-case statements, loops, catch blocks and other boolean expressions also create branches.
Our simple example had 10 branches. If you’ve been counting the number of routes through our source code, you’ll notice there are only six possible end nodes:
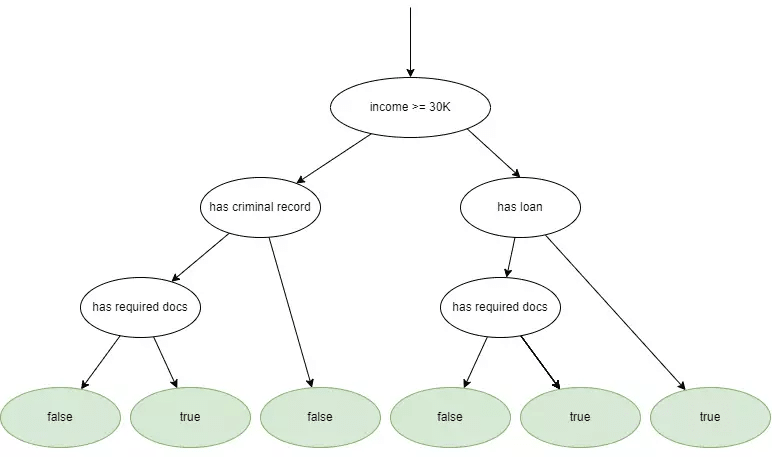
But it’s not the end nodes we’re counting. It’s the actual branches:
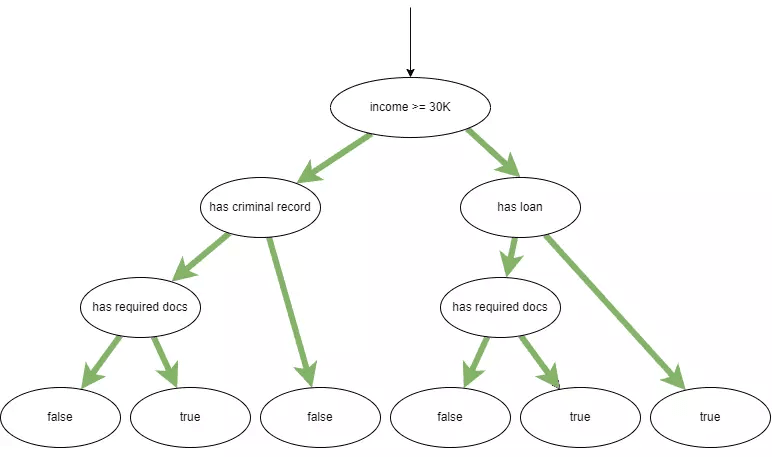
If you count the green arrows, you’ll see there are 10. And of those 10, our test only traversed three, or 30%.
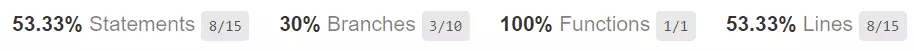
Other Types
There are other types of code coverage as well. These focus on specific parts of your code. Condition coverage, for example, looks at all and, or, and xor (exclusive or) expressions and checks if they have been tested for all combinations of true and false. Other types are loop coverage and finite state machine coverage.
But these are very specific, and the four types we saw earlier will already take you a long way in the right direction.
So, Which Type of Code Coverage Is Best?
When considering which type of code coverage is best, we should first realize that there’s a correlation between the numbers. In most projects, these numbers will go up (or down) together. But in my opinion, two of them are most useful: branch coverage and function coverage.
Line coverage is the least useful because it’s basically the same as statement coverage except that statement coverage is a little smarter. But branch coverage is even smarter. Whereas statement coverage just looks at the number of statements executed, branch coverage takes your application’s logic into account.
You could have a good score for your statement coverage, but if your branch coverage is low, it means you’re testing a big block of code in one branch while leaving several other branches untested. On the other hand, if your branch coverage is high but your statement coverage is low, you won’t need to add a lot of tests to include those few branches that contain many statements.
Finally, function coverage is a good second-best because it can quickly tell you which functions in your application aren’t tested at all.

Use Code Coverage to Your Advantage
If some of the above sounded confusing, don’t worry. Your preferred code coverage tool might not make things that complicated and just give you a single metric. If you do get multiple types, look at branch coverage first and maybe function coverage next.
But don’t try to achieve 100% code coverage. There’ll be little value in that last 5% to 10%, which makes it a waste of time, effort, and money.
There are always exceptions, of course. (Rocket systems, maybe?) But for most applications, a code coverage of 80% to 90% is a very good score.
Use code coverage to your advantage. First of all, to identify areas that are lacking tests. And second, to ensure that the coverage either remains steady or increases but definitely doesn’t drop. That would mean you’re adding new code without tests.