When engineers and engineering leaders talk about managing code, they often mean version control. And version control is an important first step to managing your code. But managing code is more than just setting up Git. Let me guide you through what I see as the different aspects of managing code.

Version Control
The first thing you’ll need to manage code is, of course, a version control system or VCS. I know—the title says managing code is more than just version control systems. But they’re an important part of it.
In theory, this “system” could be anything. In the old days, development teams used to store files in a folder on a shared server. They could download the files, make changes, and reupload them. Of course, the danger was that one developer would overwrite another developer’s changes.
Modern VCS Tools
Modern version control systems like Subversion, Visual SourceSafe, Mercurial, and Git solved this problem. With a modern VCS tool, developers can change the code and add a log entry in the VCS containing these changes. They can also add a message with details of what they changed and why. The team can then look at the log and its changes and even restore the code to run the application as it was at that point in time.
These version control systems also add extra features like branches and tags. With branches, developers can make changes without interfering with the changes of their colleagues. With tags, the team can point to specific points in time that are important to them. Mostly, tags are used to identify a version of the application.
Today, Git is the most popular VCS, and I recommend using it because it’s a superior tool and almost all developers are familiar with it. Regardless of which VCS tool you’re using (GitHub, GitLab, Bitbucket, Azure DevOps, on-premises, etc.), Git is currently the best choice for source code management.
Branching Strategy
Once you have your version control system in place, you might want to think about a branching strategy. This is the process that your team will follow to incorporate new features or bug fixes in the version control system and determine how to release certain snapshots of the version-controlled code.
There are many different branching strategies, like GitFlow, GitHub Flow, GitLab Flow, and OneFlow. I suggest having a good look at them and making a choice that best fits your needs and preferences. Keep in mind that GitFlow has lost a lot of its popularity recently because of its unnecessary complexity and because it often slows down the development pace.
GitHub Flow is the easiest flow to understand. You have one main branch that contains the code to deploy. You create branches to implement features and merge them back in the mainline when they’re ready to deploy. Simplified, this is what it looks like:

This might not be ideal for all teams, though. OneFlow adds a separate release branch to this model:
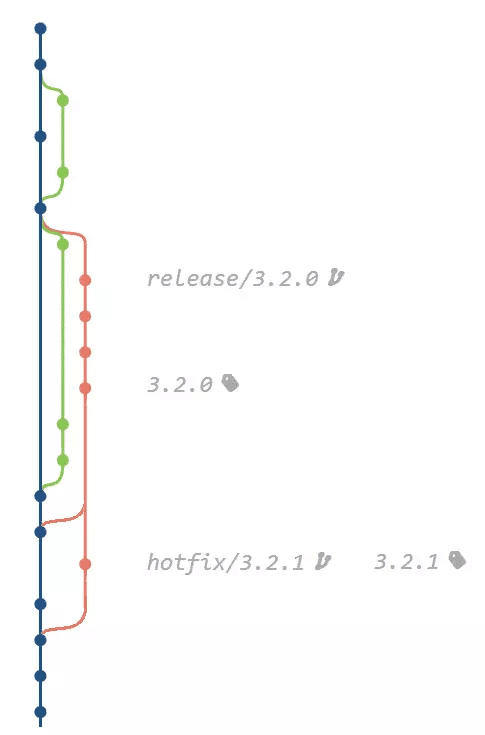
The advantage here is that there’s a branch to stabilize the release while other developers continue working on features for the next release.
Finally, if you need even more from your branching strategy, you can take a look at GitLab Flow, which allows for branches per deployment environment. This example has a staging and a production environment:
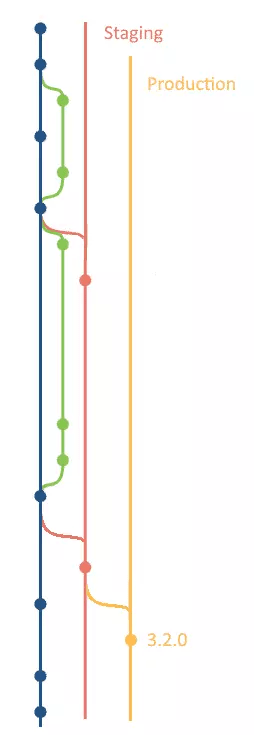
Each environment gets its own branch, and we merge into the main branch when we want to release developed features.
One word of warning: don’t design your own branching strategy. The strategies above have been tried and tested by thousands of teams in thousands of different contexts. They should be sufficient, and they’re well known, well documented, and well supported by tools.
Now that we have our version control set up and we know how we’re going to use it, we’re done, right? Not exactly, although many would think so. Let’s look a little further into how we can manage code.
Managing Features
When you implement new features, you’ve modified your existing code in some way. Apart from adding this to your version control system, you need to keep track of which features are active and which have already been deployed to production. The branching strategy may help, but there are two ways to take this to the next level.
Feature Flags
Feature flags (also called feature toggles) are, in their most basic form, just Booleans that enable or disable certain features. We can put the code for the new feature in an if block that is only executed if the Boolean evaluates to true.
You can implement more complex scenarios, of course, like using more than just true or false.
Think about a webshop that displays products that might interest the user. In normal circumstances, they could use the “basic” algorithm that displays products based on the user’s purchase history. But at the end of the year, they might set the feature toggle to “New Year” so that the application uses the algorithm that favors New Year gadgets. And maybe they have a “summer” algorithm with a focus on bathing suits and sunglasses, an “Easter” algorithm, “Black Friday,” “World Cup,” etc.
Other use cases of feature toggles are to enable or disable certain features for specific groups of users (segmented by age, interest, geographical region, etc.) or to roll out certain features for A/B testing gradually.
So feature toggles are a way of managing which parts of the code are “active” and when they become active.
They’re also useful for deactivating features that nobody needs anymore. You can just change the value of the feature toggle. If you forgot that someone still does need the feature, you can switch it on again. Once you’ve deactivated the feature for long enough and you’re sure it’s no longer required, you can remove the old code.

Versioning
Another way of controlling which code is being actively used is versioning. If managing code means being in charge of the code, you need to know which version of the code is currently in production. Remember, we have a version control system tracking many changes, and you’re probably not running the latest change on your servers.
Any modern version control system can keep track of “tags.” Basically, you put a number on the state of your code at a certain point in time. Typically, this looks something like 4.3.1 or 4.3.1.938.
I won’t get into the details of the different versioning schemas here. But again, you should choose a system and stick to it. A popular system is semantic versioning, where you increase the number based on what type of change you made:
- A breaking change increases the first number (so 4.3.1 would become 5.0.0).
- A new feature increases the second number (so 4.3.1 would become 4.4.0).
- A bug fix increases the third number (so 4.3.1 would become 4.3.2).
Some teams add the build number to the end. So version 4.3.1.938 means it was created by the 938th build on the build server. I’ve also seen teams work with years and week numbers (e.g., 2021.43.1 would be the first bug fix for the release of the 43rd week of 2021).
A good versioning system gives customers, developers, and managers a way of identifying releases and communicating changes. It helps you manage your code over time.
Managing Code Quality
Managing code also means measuring its quality. Software quality can be measured in both lagging and leading indicators.
Lagging Indicators
Lagging indicators, such as change failure rate and mean time to restore (MTTR), indicate code quality issues and look at your software delivery pipeline.
Measure and improve cycle time (your efficiency in getting code to production) to help improve your MTTR, which can limit the negative impact of your change failure rate.
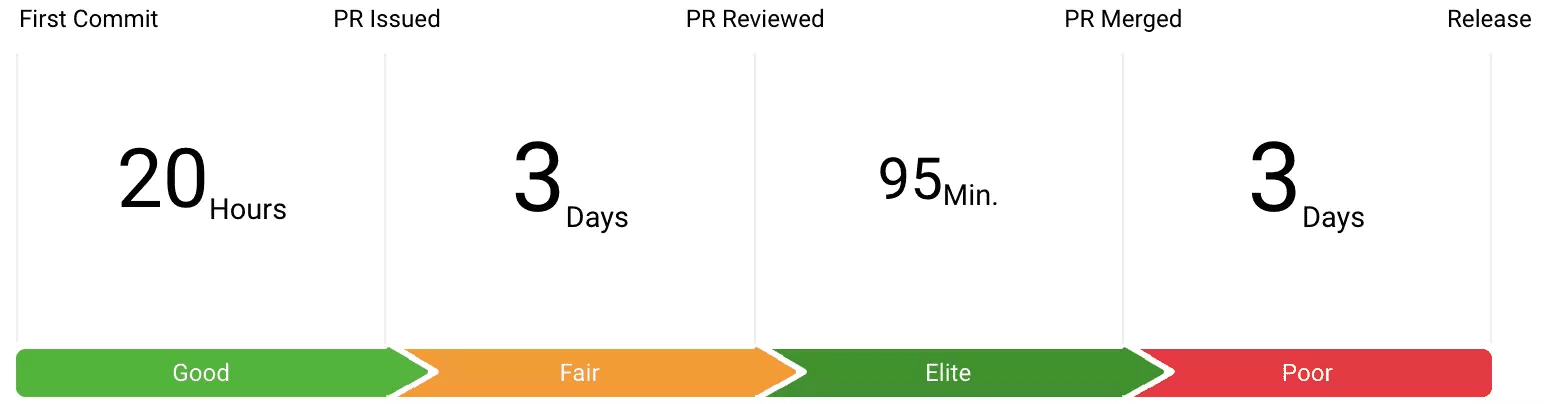
Leading Indicators
Leading quality indicators, such as work breakdown and long-living pull requests, provide a huge advantage over lagging quality indicators because they allow software teams to be proactive.
Measure work breakdown–the percentage of code creation containing new code, refactored code (change of old code), and reworked code (change of code that was recently released to production)–in LinearB as well.
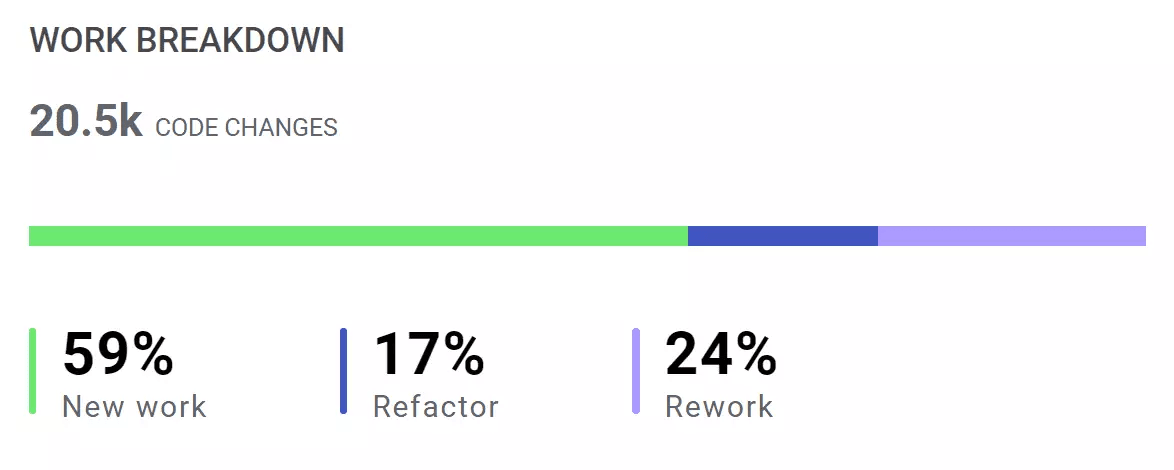
Some degree of refactored code is required for improving code quality. But a high volume of refactor in a single release is not recommended because there is a higher probability of harming existing functionality.
Additionally, a high level of rework should be analyzed further since it could indicate that the original changes were poor quality.
The pull request process also offers an excellent set of leading indicators that can be used to improve quality proactively. A few useful metrics include the number of long-living PRs, number of lighting PRs, and Pull Request review depth.
Then utilize automated team-level and personal Slack alerts to notify and encourage best practices.

So where should you begin? Start with objective metrics. Pick those you find relevant, set up the tools, and incorporate this into your daily routine.
If you’re starting with low-quality code, that’s fine. Set the minimum level, and then, start improving your code. Check regularly, ideally as part of your continuous integration pipeline.
Version Control Is Just the First Step
As we saw, managing code starts with setting up a version control system. But we need to do more beyond just setting up a VCS.
We have to think about our branching strategy. We need to think about the code that goes into production and which pieces we should phase out. There are different versioning schemas, and we should also track our code quality.
When we do all that, then we’re well on our way to managing our code effectively and efficiently.
Are you already using a VCS? LinearB integrates with GitHub, GitLab, and Bitbucket. And Azure DevOps integration is coming soon. Set up a demo to begin managing the quality of your code and software delivery pipeline.