Today I’m here to talk about code smell examples. What are they, and why should you care?
Software engineers tend to be people who get a kick out of organization and structure. We like to name and catalog all kinds of patterns and processes related to our profession, and we do this for both good and bad things. On the good side, some examples might be design patterns cataloged by the gang of four and the refactoring recipes made famous by Martin Fowler.
The list of baddies includes anti-patterns and, yes, code smells. Many people define code smells simply as “problems in the code.” As you’ll soon see, that’s not quite accurate. To clear that up, I’ll start by defining code smells and explaining why they’re important.
Then, I’ll move on to the actual code smell examples you came here for. I’ll walk you through a list of some code smells that are probably lurking in your code, explaining why they’re bad and how you benefit from eliminating them. Let’s get started.
Table of Contents
Code Smells 101
As I said, misconceptions about code smells are common, so let’s start by clearly defining the concept.

What Does Code Smell Mean?
A code smell is a sign that there might be a problem in your codebase. The rationale behind the metaphor is that, if you smell something funny, you go investigate to see what’s happening. By following your nose, you might find something spoiled in your refrigerator. The same applies to code: if you notice those signs in your codebase, then you’d better investigate what’s happening because you might find deeper issues.
Or at least that’s what the original metaphor meant. As is common in our industry, as time goes by, metaphors and terms tend to lose subtlety and become more black-and-white versions of themselves. Nowadays, like I mentioned earlier, most people simply take code smells to mean “problems in the code.”
Which definition am I following in this post? Both, in a way. Some of the code smells I’ll talk about in the list are definitely problems you should get rid of ASAP. Others might be a sign of deeper problems, but there’s a small chance you have a legitimate reason for having them.
Benefits of Tracking Code Smells
Why are code smells important? Code smells contribute to poor code quality and increases the risk of technical debt. Tracking code smells gives you a fighting chance against problems in your code. You can notice worrying trends and act preemptively against them before they become more serious issues.
5 Code Smell Examples You Should Be Aware Of
It’s time to finally walk you through the list of code smell examples. But first, a caveat.
Code smells, like design patterns and refactorings, have been cataloged for decades now. There are well-defined names for the most common ones, and they’re grouped into classifications according to their categories.
For the most part, I’ll steer clear of those classifications in this post. Don’t get me wrong; such classifications are useful, and I do encourage you to learn about them, later. But as I see this post more as an introduction, I don’t want to overwhelm you with names like Solution Sprawl and Shotgun Surgery, which can be a bit overwhelming.
Commented-Out Code
You might be surprised to see commented-out code as one of the code smell examples, but it is. For starters, it’s an example of dead code. It’s useless cruft in your codebase that adds to its overall cognitive complexity.
But there are deeper issues at play here. You might have commented-out code that is eventually uncommented in order to change application behavior—e.g. changing the URL of an external service from the local test API to the real one on the internet when it’s time to push your changes. This is a sign of a lack of engineering best practices since a combination of config files and environment variables should be used instead.
Sometimes, code is left commented out in codebases because engineers fear losing it. That indicates a lack of confidence in Git and version control, which are staples of modern software development.
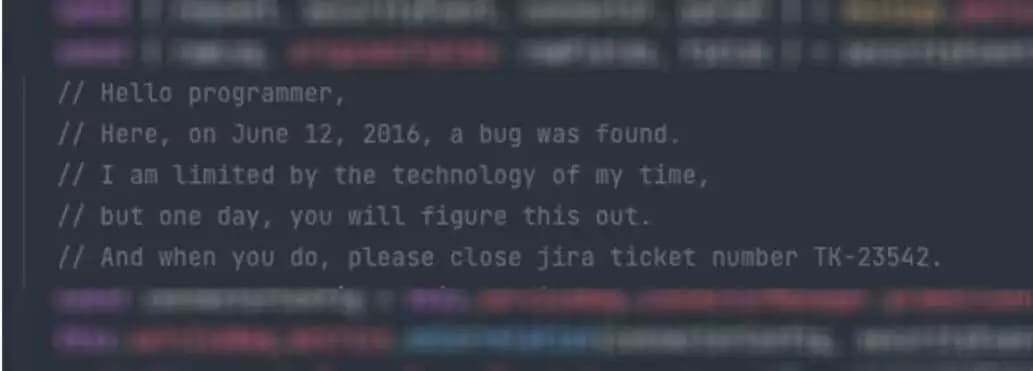
Delete commented-out code, and do it mercilessly. Git will remember it. If you follow conventional commits, you might even create an additional prefix to indicate the deletion of commented-out code, so you can easily find those commits later.
Duplicated Code
Much has been said about code duplication. A fair portion of the software design best practices and guidelines are meant to help developers avoid code duplication. Duplication represents wasted effort, it leads to bugs when the implementations diverge, and it contributes to the increase of cyclomatic and cognitive complexity.
How do you solve duplicated code? First of all, make sure you’re covered by tests. Then, start slowly removing the duplication. If the duplication is inside a single class, you can extract the duplicate portions into a new private method. If two or more classes have similar code in them, maybe that’s a sign you should merge them—or, alternatively, create a base class and make them inherit from it. Design patterns such as the template method are of help here.
What if the code duplication happens across codebases? In this case, the answer might be to extract the duplicated portions into their dedicated packages and publish them so the whole organization can benefit.
Primitive Obsession
Primitive obsession consists of using primitive types to represent domain concepts when dedicated custom types would be a better choice. Here’s a quick example in C# (don’t worry, knowing the language isn’t necessary to grasp the concept):
double distance = 5;
Ok, the distance is five. Five what? Kilometers, miles, meters, parsecs? It’s hard to say. We could communicate that using a comment, or changing the variable name to a more descriptive name. But none of that would prevent bugs caused by diverging assumptions about the unit used—e.g. someone thinks it’s kilometers, you think it’s miles, and the damage is done.
In such a case, it wouldn’t be hard to create a specific type to represent distances and then use that:
Distance distance = Distance.FromMiles(5);
This pattern is called a value object. Such a type can concentrate a lot of the business logic related to distances—further decreasing code duplication. It can also help avoid several classes of bugs, improve readability, and isn’t that hard to create.
Big Classes
You might have a legitimate reason for having a big class in your codebase, but most of the time, it’s simply a matter of bad design and lack of refactoring.
Big classes are problematic for several reasons:
- Testability. They’re usually hard to unit test, since they often have a lot of dependencies.
- Reusability. Big classes are less likely to be reused, which increases the likelihood of code duplication.
- Complexity. More code means more complexity.
- Focus. Large classes often concentrate many responsibilities, violating the single-responsibility principle and harming maintainability.
To solve big classes, you have to first—you’ve guessed it—make sure test coverage is at a comfortable level. Then, slowly start breaking the big monster apart, using patterns such as facade or adapter to make the transition gradual.
Big Methods
Long methods—or functions—are also a no-brainer when it comes to code smells. Since they’re long, they’re harder to understand and increase the cognitive complexity of the code. With more code, there are more opportunities for bugs to creep in, and also more opportunities for several logical branches, which increases cyclomatic complexity and makes the method harder to test.
Solving long methods is somewhat easier than long classes. As long as you keep the interface and behavior of the method intact—and tests help you ensure that—you can easily extract portions of the method to new descriptively-named private methods. Removing duplication also usually makes methods shorter.
Give Your Code a Nice Fragrance
Code smells are one of the most enduring metaphors when it comes to code quality, and it’s easy to understand why. After all, who likes bad smells? In this post, I gave you a definition of code smell and walked you through a small but significant list of the main ones you might find in your codebase. The list of existing code smells is huge, and I encourage you to learn more about them. Be sure to check out our posts Code Smells: What Are They And How Can I Prevent Them? and Fixing And Avoiding The Message Chain Code Smell.
Education is crucial if you want to make your code smell good, but the other side of the coin is leveraging great tools.
For instance, LinearB Project Delivery Tracker helps engineering leaders track and understand the evolution of metrics related to the health of your project, such as the investment your team is spending on bugs or how much they’re reworking and refactoring code. And our WorkerB bot helps developers improve and standardize their pull request process, which should catch code smells before they’re merged.
With the dual combo of education and good tools, you increase the odds of detecting code smells and other bad trends in your codebase and project and fixing them before they give you a headache.