Code isn’t uniform across a codebase. The code in some parts of the application might be very simple, almost trivial. On the other hand, another area of the codebase might feature code that’s more complex.
Similarly, code varies regarding how critical it is. The core business domain portion of your application is highly critical. However, you might have parts that are less important, even to the point of being eligible for extraction into independent packages.
Today, we’re here to discuss one of those criteria, namely, cognitive complexity. What is cognitive complexity? Why is it important you know about it? Is it possible to fix it? These—and more—are the questions we’ll answer in this post.
Let’s dig in.
Table of Contents
- What Is Cognitive Complexity?
- What Is Programming Cognitive Complexity?
- Why Is Cognitive Complexity Dangerous?
- What Causes Cognitive Complexity?
- Cognitive Complexity in Software: Can You Fix It?
What Is Cognitive Complexity?
First, we need to bear in mind that, before its role in software engineering, cognitive complexity was already a concept in psychology. Only more recently did it enter the domain of technology, particularly with its importance in human-computer interaction.
But how do we define it? This study, for instance, defines cognitive complexity as “how complexly or simply people think about a particular issue.” As you can see by reading the page, the study defines complexity almost as a synonym for sophistication.
In other words, an idea is more cognitively complex if it causes you to hold more concepts in mind and think about how they relate to each other. A simple example of this is the number of moves and countermoves available in Checkers vs. Chess.
What Is Programming Cognitive Complexity?
Based on what you just read about cognitive complexity in general, it becomes easy to adapt the concept to software engineering. Cognitive complexity in software development is a measure of how hard it is to understand a given piece of code—e.g., a function, a class, etc. This has important implications regarding the quality of a software project.

Why Is Cognitive Complexity Dangerous?
High cognitive complexity is one of those measurements in software that is both a symptom of possible problems and a cause of further issues. So solving it is immensely profitable since that means fixing existing issues and preventing future ones from happening.
We’ll cover the causes of cognitive complexity in code next. Right now, let’s focus on some of the problems it can create. Three common problems cognitive complexity in code creates are:
- Complex code is more susceptible to bugs. If a piece of code is harder for engineers to understand, it’s more likely they’ll introduce defects to the code.
- Complex code makes it harder to onboard new team members. When you join a team, it takes some time to get up to speed with the new codebase. That’s completely normal. However, highly complex code might make such a learning curve unnecessarily steeper.
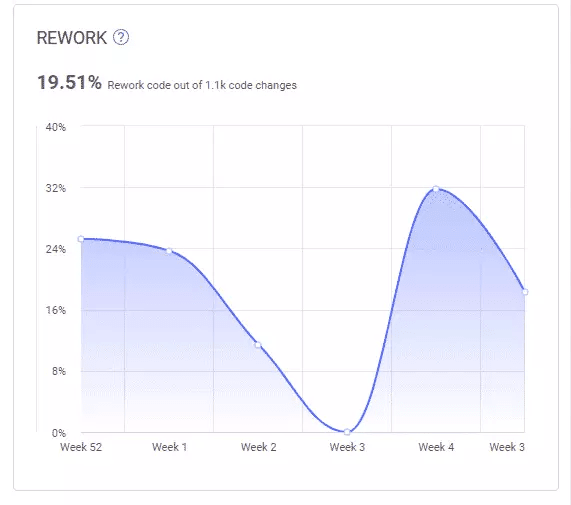
- Complex code causes more rework. If a given piece of code is too complex, developers might write new code that interacts with it in the wrong way. Then, upon finding out about the error, they’ll have to rewrite their recently written code.
The process of rewriting recently merged code too often and too soon is called code churn, or rework. Code churn is a predictor of code quality problems. You can easily track your own rework rates using tools like LinearB.
What Causes Cognitive Complexity?
Let’s now discuss some of the main causes of cognitive complexity. Keep in mind that the following causes differ in their nature.
Some of them are problems within the project itself. There’s also a single reason—high essential complexity—that something is intrinsic to the domain itself and it’s unavoidable. And lastly, a final reason for cognitive complexity is an education problem: these issues are caused by an engineer’s lack of knowledge and experience.
Cyclomatic Complexity
Cyclomatic complexity measures how many execution paths exist inside a code block—e.g., a function. This metric is particularly important when it comes to testing since it helps define the minimum number of test cases you’d need to obtain for complete branch coverage.
However, cyclomatic complexity is also a factor in cognitive complexity. Code that has a high cyclomatic complexity is, generally speaking, harder to understand and navigate.
Poor Naming
If you’ve been a software engineer for any reasonable amount of time, you know how hard naming is. Unfortunately, that means that many, if not most, names in our codebases aren’t the best they could be. That definitely leads to more cognitive complexity since code readers have to make more effort in order to figure out what the poorly named code artifacts are for.
Poor Architectural Decisions
Cognitive complexity can also be affected at the architectural level. Too much coupling between modules is one example of poor architecture that might reflect badly on the general understandability of the system.
Another example? Poor separation of concerns. For instance, business domain code related to presentation layer concerns.
Such mismatches are a problem for cognitive complexity: engineers are confused—and rightly so—when they change code in a given layer only to have it create consequences in seemingly unrelated parts of the application.
Large Functions or Classes
Large pieces of code—for instance, classes, functions, or modules—aren’t necessarily more complex. However, they do represent a higher probability of more complexity, simply due to their length: more code = more opportunity for complex code.
High Essential Complexity
In this article by Mark Seemann, you can read about the differences between accidental and essential complexity. Simply put, accidental complexity is the “bad” type of complexity. We add accidental complexity to our projects due to our limitations as software engineers—and as human beings, really. This is the type of complexity we ought to reduce in our projects.

Essential complexity, on the other hand, is the type of complexity that’s intrinsic to the domain we’re working on. There’s no way to reduce it further, and thus, we have to cope with it. Some domains are simply more complex than others, and that complexity affects the overall cognitive complexity of the project.
Not Following Established Conventions
Some programming languages or frameworks are known for being highly opinionated, down to the project folder structure and the naming conventions you should apply to files, functions, classes, and the like. Alternatively, there are tech stacks that are less opinionated. Even still, they at least define common coding standards that should be followed by everyone writing code in that language.
There are engineers who find such conventions oppressive and attempt to go against them. That creates more cognitive complexity because people who are used to the conventions will have a harder time finding their way into the project.
Lack of Familiarity With the Domain
The final two items in our list are the ones that can be solved through education. First, we have a lack of familiarity with the domain.
Suppose you’ve just joined a company that writes software for law firms, but you have close to zero knowledge in that domain. In that case, you’ll naturally have a hard time understanding the more domain-heavy portions of the codebase, comparable to your coworkers who have been there longer.
Lack of Familiarity With the Language or Stack
Let’s say that, after being a Java developer for many years, you suddenly see yourself working as a Ruby on Rails engineer. At least in the beginning, you’ll struggle when navigating the codebase since you’re not experienced with the tech stack in use, despite being an experienced professional in general.
Cognitive Complexity in Software: Can You Fix It?
You’ve just been treated to a brief yet complete explanation of cognitive complexity in software. Now you understand what it is, what its causes and consequences are, and why it can be quite a headache. The next logical question for most people now would be how—and whether—you can fix cognitive complexity.
You might be familiar with the saying that you can’t improve what you don’t measure. So the first step to fixing cognitive complexity is measuring it.

Sure, some aspects of cognitive complexity are subjective. However, there are objective ways in which you can assess cognitive complexity. And that’s through the tracking of related metrics.
3 Metrics For Measuring Cognitive Complexity
Predictors of cognitive complexity include factors such as cyclomatic complexity and code length that are totally measurable. Also, code that gets rewritten too often—in other words, code that suffers a lot of churn or “rework”—is usually a red flag.
One of the common reasons behind such rework is the fact the developers are struggling with the code. Thus, it’s a sign that the code might be too complex.
Here are three metrics we recommend you begin tracking to day to improve cognitive complexity in your codebase:
Code Refactor – Refactored represents changes to legacy code that was modified. LinearB considers legacy code any code that was added to the codebase more than 21 days ago.
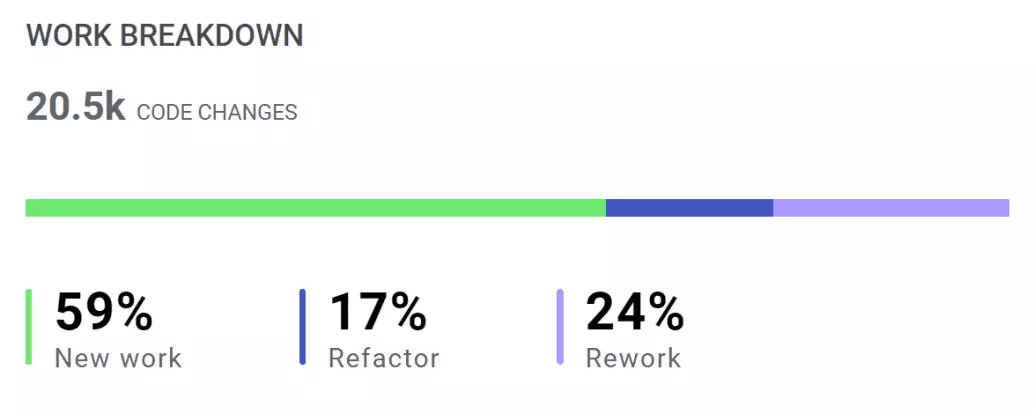
Some degree of refactored code is acceptable and even required for improving systems quality. High volumes of refactor in a single release are not recommended since they have higher probability of harming existing functionality.
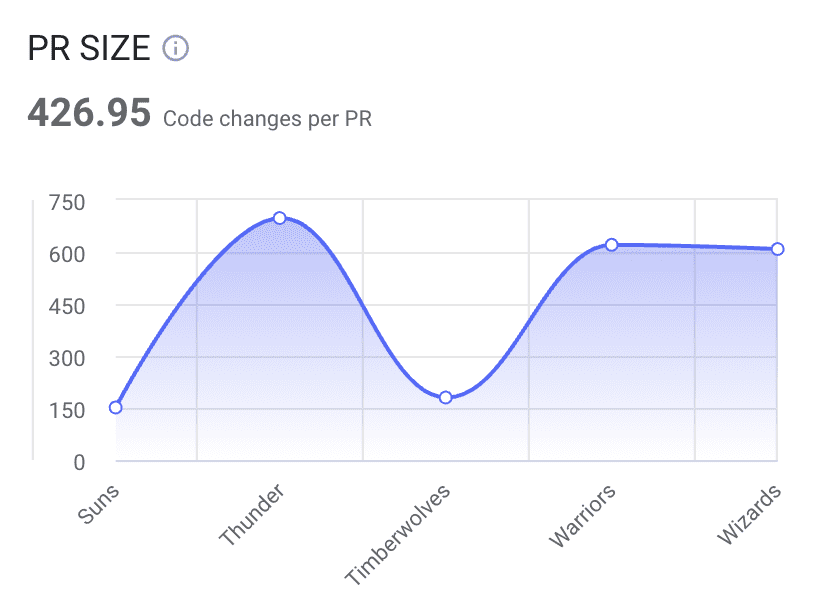
Pull Request Size – Pull request size is a metric calculating the average code changes (in lines of code) of a pull request.
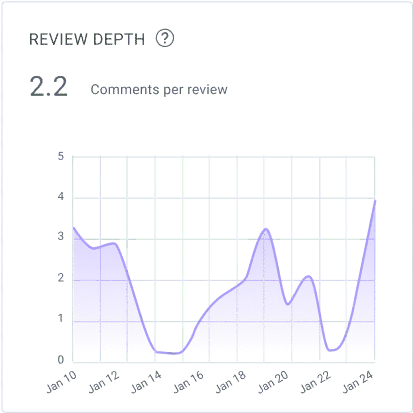
Review Depth – Review depth measures the average number of comments per pull request review. This metric is an indication regarding the quality of the review and how thorough reviews are done.
What’s better than measuring how difficult code might be for your developers? Using our adaptive WorkerB bot to implement quality gates that warn your team and reinforce cognitive complexity best practices. Set customized team goals around PRs with high rework, too many changes, basic reviews, etc.