Why are metrics important?
Let’s say you own a little store that sells socks. If you get visitors daily, you may think this makes your business a success. But, of course, the number of visitors doesn’t paint the whole picture. You’d also be concerned about revenue and costs as well as the number of purchases, customer satisfaction, and repeat customers. And what about complaints?
You can compare the number of visitors to the number of people who purchase something; that becomes a more useful metric than just visitors alone. If you compare the number of visitors’ purchases to those satisfied with their purchase, you get another useful metric.
The right metrics give us concise, specific measurements of performance. They enable us to know whether things are going well and where we can improve.

In this post, you’re going to learn about mean time to restore (MTTR), a metric that shows how efficient an engineering team is at fixing problems. We’ll then look at other incident metrics as well as the other metrics in the DORA metrics framework.
Table of Contents
- What is Mean Time to Restore?
- How to Calculate Mean Time to Restore
- Incident Metrics
- DORA Metrics
- Importance of MTTR and DORA Metrics
- Parting Words on Mean Time to Restore
What Is Mean Time to Restore?
Mean Time to Restore (MTTR) is the average amount of time it takes to recover from an incident. An incident is an event that leads to an interruption of normal operations. In other words, they are anything that cause downtime, like bugs or external system outages.
Mean Time to Restore is a key metric in any incident management system, since it captures the severity of the impact – that is, how long the application was down for.
A lot of attention is paid to optimizing application performance while it’s live. But keep in mind that when your application is down, its performance is 0. Time spent avoiding downtimes should be viewed as a crucial investment in application performance.
I should note before going any further that the acronym MTTR actually stands for four things! Mean Time to Restore is often used interchangeably with Mean Time to Repair and Mean Time to Resolve, although some people draw a distinction between the terms.
What’s important to know is that Mean Time to Respond is a very different metric from the other three. It measures how long it takes to start addressing an issue that has arisen. (Below we’ll discuss the metric Mean Time to Acknowledgement which is similar.)
How to Calculate Mean Time to Restore
MTTR is calculated by adding up total downtime and dividing by the total number of incidents within a particular time period. The formula is simple:
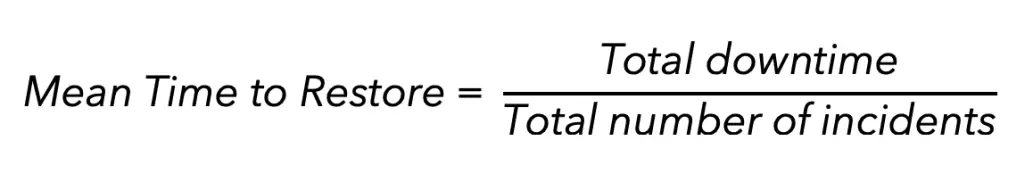
For instance, say your car breaks down three times in two weeks. It took, respectively, two, five, and eight hours to fix, which adds up to 15 hours of total downtime. The MTTR for that two-week period is five hours:
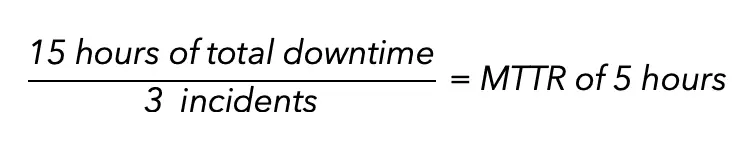
How to Reduce MTTR
Long and frequent downtimes can cause your company to contravene service level agreements (SLAs) which will directly result in lost revenue. This means that the business side also has a vested interest in lowering MTTR.
MTTR should be as short as possible. High-performing engineering teams typically recover from incidents within minutes or a few hours and can fix multiple issues in a day. Here are some ways MTTR can be lowered and thus improved:
- Build out continuous integration/continuous delivery (CI/CD) systems that automate monitoring, testing, and failure detection.
- Make small changes frequently. Deploying in fixed intervals during the day ensures failures can be easily tracked, and the changes that cause failures can be fixed or rolled back. You could also use feature flags to turn off changes made in recent deployments.
- Have the right tools, processes, and permissions in place. The developers working on a project should have all they need to fix issues immediately. Also, it’s important to maintain the same team members throughout the development process so that the people most familiar with the code are available to address issues when they arise.
- Consider creating a devops team. These are quickly becoming popular as companies appreciate the importance and complexities of keeping their applications up and running.

What Is a Good MTTR?
Generally, incident response times should be as short as possible, but a good rule of thumb is that MTTR shouldn’t exceed a day. That said, even 24 hours might be too long for some teams; a lot can happen in that time.
Remember, high-performing teams can recover within a few hours, and every second in the recovery period counts. As a team lead, you’ll have to decide what is feasible for your team and what makes the most sense for your business and your application.
It’s best to start by establishing your team’s current MTTR. You can then set a goal to work toward, track your progress, and see how much your team improves. If the team meets the goal, you can set a new one. If the goal was too ambitious, scale it back. The specific target is not as important as driving toward improvement.
LinearB can facilitate this entire improvement process – from establishing the baseline, goal setting, and progress tracking. We have tools, like our WorkerB automation bot, that can do things like notify the team of a pull request that contains code that could cause a bug so that you can prevent an outage all together.
Incident Metrics
We’ve established that MTTR tracks incident recovery and that its aim is to reduce downtime. However, in the SDLC, recovery is only one step in an incident response system. Tracking other incident metrics alongside MTTR will provide more insights into the reliability of an application.
Let’s look at a scenario: In a 30-day month, a software system breaks down four times. It takes the engineers 24 hours in total to resolve the four incidents. This puts MTTR at six hours.
We’ll refer back to this example as we explore other incident metrics below.
Mean Time to Acknowledge (MTTA)
Once an incident occurs, how long is it before your team acknowledges the issue and gets to work diagnosing the problem? That’s what MTTA measures. MTTA is the average time it takes an engineering team to acknowledge a new incident. It is calculated as the sum of the time between detection and acknowledgment of the issue, divided by the total number of incidents:

Suppose it took the engineers a total of 60 minutes from detection to acknowledge for each of those four incidents. MTTA will be 15 minutes (60 minutes / 4 incidents = MTTA of 15 minutes).
Before you can recover from an incident, your team must become aware of it. A lower MTTA will reduce downtime and improve MTTR.
Mean Time Between Failures (MTBF)
MTBF is the average time from one incident that causes failure to the next. This is a key failure metric that captures the frequency of system failures. It’s the total hours of operation, or uptime, divided by the number of incidents:
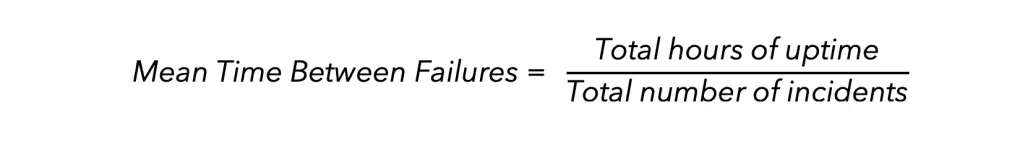
From the above example, a 30-day month has 720 hours. The total downtime was 24 hours, so uptime is 696 hours. As a result, MTBF will be 174 hours (696 hours / 4 incidents = MTBF of 174 hours).
DORA Metrics
MTTR is one of four key metrics identified by the DORA (DevOps Research and Assessment) team, a Google research group. The DORA metrics together capture the overall health and performance of software engineering teams.
The other DORA metrics are:
- Deployment Frequency
- Mean Lead Time for Changes
- Change Failure Rate
Let’s briefly look at each one of these.
Deployment Frequency
Deployment frequency measures how often new code is deployed into production. It measures the speed or agility of a team. Elite teams deploy multiple times a day.
Mean Lead Time for Changes
Mean Lead Time for Changes, or change lead time, is how long it takes to commit changes to a project. It’s measured from the start of development to when the code is ready for deployment – that is, when the code has gone through all necessary checks.
Engineers who want to improve their efficiency can go beyond this single metric and measure cycle time. Cycle time spans the time it takes for new changes to be developed, tested, and then deployed.
Change Failure Rate
Change Failure Rate is the percentage of code changes that cause failures in production. To calculate it, count the number of deployments that lead to failures and divide by the total number of deployments.
Importance of MTTR and DORA Metrics
MTTR and the rest of the DORA metrics may seem simple, but this is only because they were carefully selected after six years of research. The DORA team at Google surveyed thousands of engineers and concluded that teams that did well across these four metrics recorded high levels of customer satisfaction and profitability and also provided the most value. DORA metrics are now the industry-standard way of tracking development team performance.
LinearB’s Co-Founder, Dan Lines, has spoken with loads of engineering leaders about the metrics they rely upon. We put together a compilation of what they had to say about the immense value of DORA metrics specifically:
Parting Words on Mean Time to Restore
The main goal of any software engineering team is to deploy as often as possible, as efficiently as possible. Knowing the right set of metrics to monitor is the first step toward achieving this goal.
I hope that by now you are convinced that MTTR is a key metric because it tells you how quickly your team can get your application up and running again after it goes down.
MTTR is a great starting point but keep in mind that metrics don’t work well in isolation. MTTR works best alongside the other DORA metrics.
LinearB makes it easy to implement monitoring systems and start tracking and improving DORA metrics in your engineering org. We integrate with Git and SDLC management tools like GitHub, GitLab, and Jira to generate metrics which you can see in easy-to-read charts. On top of this, our goal-setting framework and automation tools will help your team start improving immediately.