Code complexity is a beast to deal with. Since a project’s goals and functionality change over time, the codebase generally grows and evolves. In the end, you wonder why huge sections of the codebase are even in there.
In addition, there can be significant problems with code complexity as a project comes to a close. If you’re a team lead, you and your dev team end up spending a horrendous amount of time reviewing extremely complex code and trying to iron out the last set of bugs.
This article will explain what code complexity is and how to measure it. Why does it matter? Because once you’re able to measure the complexity of the code, you can manage it. Complexity might be a part of every codebase, but you can strive to put a design and structure in place that handles it and manages the side effects.
Defining Code Complexity
The complexity of a given piece of code has to do with just how complicated and unwieldy it is for a developer to understand. This idea makes intuitive sense. For example, the picture at the top of the article is way more complex than, say, a picture of a single rose on a white background.
In particular, the codebase’s size can make it difficult for anyone to wrap their heads around exactly what’s going on. This becomes even more of a problem when the code begins to have multiple paths through conditionals, has several dependencies, or is coupled with other parts of the codebase.
Just think about the following two example functions:
a)
def squared(x):
x2 = x * x
return x2
b)
def squared_conditional(lst):
result = []
for x in lst:
if x > 3:
x2 = x * x
else:
x2 = x * x * x
result.append(x2)
return result
Just by looking at the two functions in a) and b), you can easily see that b) is more complex because there’s a lot more going on. In the second example, there are far more lines, there’s a for loop, and there’s an if-else statement that makes it more complex.

Why Code Complexity Matters
Okay, great, so it’s clear that some code is more complex than other pieces of code. But why does it matter? Some code has to be more complicated because it has greater functionality. So it needs to be more complicated, right?
Some code needs to be more complicated, sure. But we’re looking for code that’s unnecessarily complex.
There are dangers with having highly complex code. You run the risk of increased code defects, increased time fixing bugs, and unreliable testing.
Robert C. Martin pointed out that “the ratio of time spent reading versus writing is well over 10 to 1.” You don’t want to increase the reading side of the ratio any further by producing unnecessarily complex code. Decrease unnecessary complexity, and you will decrease the time to production.
How Does This Keep Happening?
As Brandon Pearman points out, a codebase can become more complex through no fault of a single developer on their own. Each dev comes in each day and adds their simple, efficient line of code to the codebase. But over the project’s lifespan, every developer coming in every day adds up. It’s the compound effect!
Now, you may think that this sounds impossible to control. Obviously, you want your team coming in and coding each day. (That’s why they get paid!) However, don’t fret. It’s possible to reduce unnecessary code complexity.
Below, I provide three avoidable causes of unnecessary complexity. You can avoid or lessen each of these problems. Doing so is better for everyone, as developers want to spend less time fixing bugs and more time producing new products.

Cause #1: Making Irreversible Decisions
Making irreversible decisions in the codebase will cause developers to have to hack around those decisions whenever they cause issues later down the line in the product’s life cycle. Each one of these workarounds will add unnecessary complexity to your codebase. Thus, you must have clarity and visibility with where you want your project to go so that you aren’t trying to backtrack in the future. Design a plan for any irreversible decision while acting quickly on easily reversible decisions.
Cause #2: Coupling
Coupling is the connection between one piece of code and another. Keep it to a minimum. If a problem arises with one piece, you’ll need to adjust each piece that’s coupled to it. A developer can fall down the rabbit hole trying to find out which coupled function didn’t get updated.
Avoid this problem by maintaining solid principles and guidelines for your team. That way, your code will remain decoupled and flexible to future change.
Cause #3: Poor Readability
Refer back to Robert Martin’s quotation. Your team will be reading the codebase significantly more than writing code into it. So if the code is too complex and lacks readability, it’ll continue to slow down the production process.
Developers have great control over readability. With an increase in readability comes an increase in the quality of the code.
What Can You Do About Reducing Code Complexity?
The simple first step is to measure it. If you can measure it, you can manage it.
This is where you can upgrade to making data-driven decisions that no one can argue with. Luckily for us, several metrics can help measure code complexity and help you identify potential areas for improvement within the codebase.
- Cyclomatic Complexity
- Lines of Source Code
- Lines of Executable Code
- Coupling/Depth of Inheritance
- Maintainability Index
- Cognitive Complexity
- Halstead Volume
- Rework Ratio
Let’s look at each of these.
Cyclomatic Complexity
This metric is by no means comprehensive, but it can be a valuable asset to determining the complexity of a given piece of code. Initially developed in 1976 by Thomas McCabe, it measures the number of linearly independent paths through a program’s source code. You compute it by using the control flow graph of the program.
Here’s an example of a control flow graph:

Cyclomatic complexity measures the number of nested conditions within the code, such as those created by for, if/else, switch, while, and until. The greater the number of conditions (as in example b from above), the greater the complexity.
The cyclomatic complexity is the number of different pathways through the control flow graph. You can calculate it this way:
Cyclomatic Complexity = E – N + 2 * P
where E = number of edges, N = number of nodes, and P = number of nodes with exit points.
Lines of Source Code or Lines of Executable Code
These metrics are straightforward to calculate and purely look at the number of lines of code. Source code measures the white space in the code as well, while executable doesn’t.
Coupling or Depth of Inheritance
This measures how intertwined and dependent a class or function is in relation to all others in the codebase.
Maintainability Index
This single value measures how easy it is to maintain the code. It’s a combination of the four metrics above (cyclomatic complexity, lines of source code, lines of executable code, and depth of inheritance/coupling).
Cognitive Complexity
This measures the amount of cognitive effort required to understand the code’s flow. You compute cognitive complexity similarly to cyclomatic complexity. However, it doesn’t increment with if statements that have logical operators in them. Cognitive complexity only increments once with switch cases, but it does increment complexity with nested flow breaks.
Halstead Volume
This measures the amount of information in the source code. It counts the number of variables and how often they appear.
Rework Ratio
Your Rework ratio is the percentage of recently delivered code your team is already rewriting, also known as code churn. While this isn’t a direct measure of code complexity, it is a potential indicator of overly complex code you may want to keep an eye on.
Typically, rework occurs because there’s an issue in the quality of your code review process, such as superficial reviews that don’t look for code complexity indicators.
At LinearB, we track your Rework Ratio as a segment of your overall Work Breakdown.
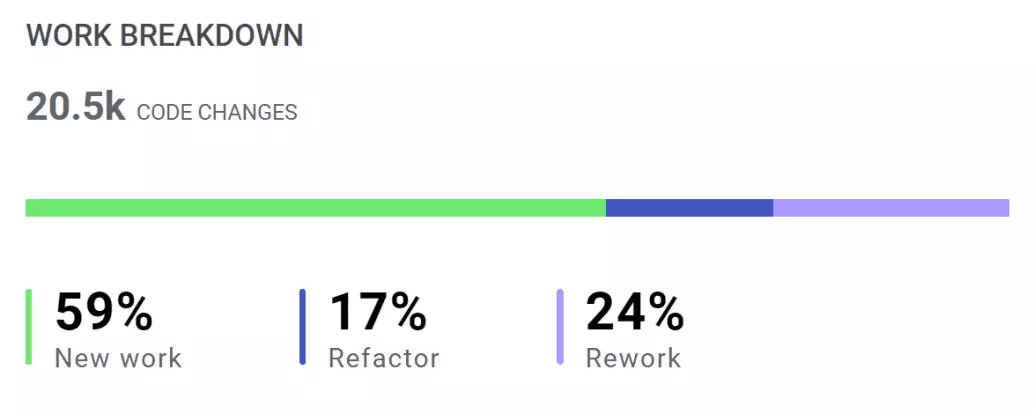
Rework isn’t necessarily a problem. Even the most skilled developers have code rewrites. A low rate of rework is expected, but a high rate of rework is definitely a problem.
Which is why it’s one of nine metrics we included in our Engineering Benchmarks study of nearly 2,000 engineering teams. We needed to determine what the industry standards of good and bad Rework Rate, among other metrics, should be. For Rework Ratio, the average team was reworking more than 11% of their code, but elite teams were able to keep it under 8%.
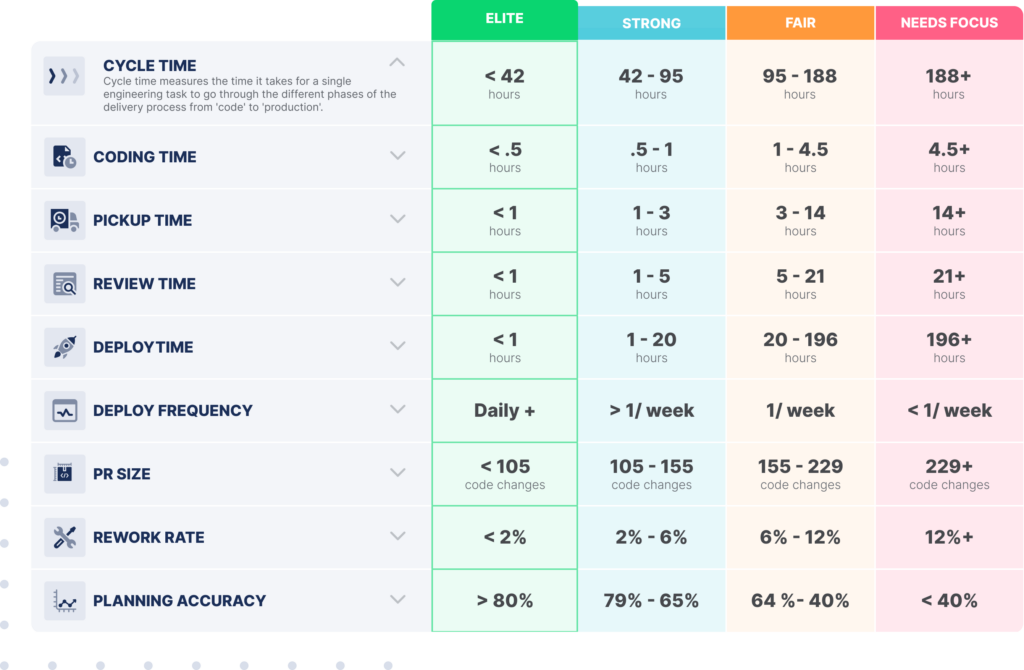 Want to learn more about being an elite engineering team? Check out this blog detailing our engineering benchmarks study and methodology.
Want to learn more about being an elite engineering team? Check out this blog detailing our engineering benchmarks study and methodology.
Continuous Maintenance
The metrics in this article are fantastic indicators to use throughout your software engineering projects. They’ll allow you to catch any potential fallacies before they become horrendous monsters rearing their head out of the codebase.
Make your life easier! Begin tracking code complexity before it becomes a problem. Your future self will thank you.
My suggestion is to get a demo of LinearB. It’s a free tool that correlates data across your tools to provide team and organization-level metrics within minutes.
Then, once you’ve established your baseline metrics, LinearB helps you identify areas of improvement and gives you guidance on how to tackle improvement with Team Goals. And our WorkerB bot automates developer workflow optimization to keep your team on track with your goals to reduce code complexity and improve code quality.
 Want to improve your engineering processes at every level? Get started with a LinearB free-forever account today!
Want to improve your engineering processes at every level? Get started with a LinearB free-forever account today!