Technical debt is one of the most enduring metaphors in the software world. There are plenty of reasons for that. The metaphor uses an intuitive concept—who doesn’t know financial debt? It also offers the possibility to think of software quality in a way that sounds objective and quantifiable—definitely less subjective than something like “code smells”—which appeals to our analytical brains.
Actually, this is a common critique of the tech debt metaphor: that tech debt is far from being as quantifiable as it’s purported to be. In this post, I’ll prove otherwise, showing you how you can measure technical debt in practical ways. However, before getting there, it’s important to convince you that technical debt metrics are worth your time. So, I’ll do just that.
I’ll start with a brief definition of the term, with a link to a more in-depth definition in case you need it. Then I’ll cover the reasons why you should care about measuring technical debt. Finally, I’ll walk you through the metrics you should track and how to do it.
Let’s get started.
Table of Contents
- What Is Technical Debt?
- Why Should You Measure Technical Debt?
- Measuring Technical Debt: Identify High-Risk Areas
- Software Quality: To Measure It Is to Improve It!

What Is Technical Debt?
We do have a more in-depth exploration of the concept of technical debt. If you don’t have time to review it now, I’ll treat you to the short version here.
Technical debt is a metaphor proposed by Ward Cunningham. In a nutshell, it means consciously picking an easier solution over the optimal one in order to gain time.
In the metaphor, paying off the debt refers to changing the design to the correct, optimal solution. If you don’t do it, you’ll have to pay interest, which takes the form of additional work in the future due to maintenance difficulties introduced by the “shortcut” you took.
Why Should You Measure Technical Debt?
If you subscribe to the technical debt metaphor, you probably consider it to be a problem and want to solve it. Great! How would you go about that?
There are a plethora of practices you can use to keep technical debt at bay: automated testing, code reviews, and refactoring, just to name a few. However, I believe that before you start tackling technical debt you should measure it. Why?
Solving technical debt can be quite a time-consuming and expensive endeavor. Adding unit tests to a legacy codebase, for instance, is incredibly hard. Remember that professional software development is always an economical enterprise, and as such, decisions must make financial sense.
Here are a few reasons to measure technical debt:
- It allows you to assess the financial viability of the endeavor. Maybe a portion of the code is in bad shape, but it’s not a critical area and it doesn’t suffer a lot of changes, so improving it doesn’t make sense.
- It can help you find an easier solution. You might find that your bad “scores” are caused by a subsystem that will soon be decommissioned. So, fixing it doesn’t make sense since you’ll soon throw it away.
- It can help you identify low-hanging fruit. You might discover portions of the codebase that are relatively easy to fix, allowing you to score some early wins right away.
To sum it up, you should measure technical debt before you set out to fix it because doing that will help you save money. You might even find out that your technical debt isn’t as bad as you previously thought and decide that it’s actually a good idea, economically speaking, to not fix it.
Measuring Technical Debt: Identify High-Risk Areas
Measuring technical debt is mainly a matter of identifying some key metrics that, together, can offer you a big-picture view of your work. You need to be able to detect which portions of your codebase offer the higher risk so you can take a risk-based approach and make the most economical decisions.

Keep Track of Complexity
One of your first steps when trying to identify high-risk areas should be tracking complexity. Complexity in code can take many forms, but the most straightforward metric for you to track is cyclomatic complexity. In a nutshell, cyclomatic complexity is a measure of how many logical branches there are inside a given function or method.
Cyclomatic complexity correlates with the minimum number of test cases you need to achieve full branch coverage of a function. Code with lower cyclomatic complexity is typically easier to understand and maintain, which means reducing cyclomatic complexity contributes to decreasing the overall cognitive load of a given piece of code.
Track Rework Ratio
Engineers are more likely to introduce defects to the areas of the codebase they change most often. Also, the fact that a given piece of code suffers too many changes is in itself a warning sign. That might be due to lack of knowledge or experience, poor code review practices, or even requirements being poorly communicated to the engineer.
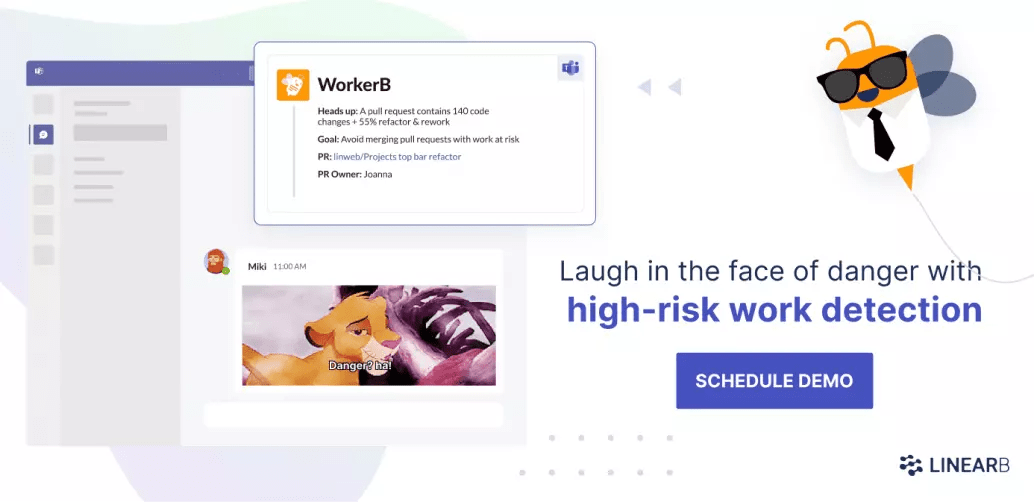
This metric is called churn, or the rework ratio, and you should track it and strive to keep it low. A high rework ratio is a sign things aren’t quite right and also a potential cause of further problems. Code with a high proportion of rework has a higher risk of introducing bugs into production. LinearB will alert you to high-risk code so that you prevent system outages.

Quantify Your Testing Efforts
Software testing is another investment you need to quantify. Not having a comprehensive suite of automated tests—especially unit tests—is a terrible sign for a codebase when it comes to technical debt. Without tests, engineers aren’t confident to make changes—such as refactoring—that benefit the health of the codebase because they fear breaking things. When that’s the case, the overall quality of the code rapidly decays.
One of the most common forms of quantifying testing efforts is tracking code coverage. There are different types of code coverage, among which I consider branch coverage to be the most useful.
Coverage is a funny metric since a low value is certainly a warning sign, but a high value doesn’t necessarily make you rest easy—because coverage doesn’t tell you anything about the quality of your current test suite. However, it’s certainly useful to define a threshold—for instance, 80%—and consider everything below that a high-risk area.
Calculate Risk and Add Importance to the Mix
With the previous metrics—especially the rework ratio—you’ll be able to understand the risk of a given part of the codebase. For instance, a piece of code with a high rework ratio, low code coverage, and high code complexity is certainly high risk. To learn even more about how you can leverage data to manage risk in software, check out this post.
However, parts of a codebase don’t differ only regarding risk. They also vary in how important or critical they are.
If you had the budget to fix only one module in your app, which one you would choose?
- A medium-risk module with code that’s critical for your company
- A high-risk module comprised of utility functions
I think the answer is quite obvious. Additionally, if your codebase contains too much noncritical code, consider extracting this code to external packages. That way, you can improve the signal-to-noise ratio when measuring technical debt in the codebase. In addition, you promote the reuse of code inside your organization.
Software Quality: To Measure It Is to Improve It!
Technical debt—and code quality as a whole—doesn’t have to be a fuzzy, subjective concept. On the contrary, you can and should measure it. That’s vital if you want to have a chance at fighting and defeating code rot.
Most importantly, by quantifying code quality with metrics, you’ll be able to make informed decisions that make economical sense. Sometimes you shouldn’t improve a given piece of code. I know that sounds awful. It hurts me even typing it!
But remember that there’s an economic imperative behind our work as software engineers. Measuring technical debt helps us decide when to tackle it and when to leave it alone.
With LinearB, you can manage technical debt, as well as other key dimensions of software development like engineering efficiency and code quality. With tools like data dashboards and our WorkerB automation bot, you’ll be able to drive improvement in your development teams so that you ship better code faster.